")

Poland has received an invitation from the European Commission to participate in the third, currently being launched phase of a pilot project aimed at linking the learning outcomes of qualifications with ESCO skills. We spoke with Leopold Będkowski (IBE), a member of the working group on ESCO, on the lessons learned from the previous pilots and the difficulties and challenges before the next phase of the project
Interview with Leopold Będkowski, Expert in Data Science at the Educational Research Institute, Warsaw
1. What, in brief, did the two phases of the pilot consist in?
Our participation consisted in piloting an IT tool for linking learning outcomes to the ESCO skills (ultimately: linking qualifications to ESCO occupations). As part of the pilots, we tested and discussed the IT tool prepared by the team at the European Commission and referenced a set of several dozen qualifications from the IQR (Integrated Qualifications System) to ESCO data.
The first phase of the pilots focused on testing a prototype of the system that recommends matching skills from ESCO based on a machine learning engine (machine learning is a branch of the so-called artificial intelligence). The IT tool was tested by pasting text with the learning outcomes from a selected qualification; the tool then attempted to tokenize the text. Tokenization refers to the process of breaking down text into a sequence of tokens, i.e. more elementary fragments (examples of tokens can be words, sentences, etc.) - in the case of the ESCO IT tool, the tokens were learning outcomes. And, finally, the machine learning model suggested a list of the most relevant ESCO skills for a given learning outcome. The human's task was to evaluate the recommendations proposed by the model and, where possible, link the outcome to the most relevant skill from ESCO.
In the second phase, we tested another version of the prototype of the tool, which was developed based on the comments and recommendations formulated by the participants during the first phase of the pilot. In addition to the artificial intelligence-based skill recommendation module, the tool offered a number of new features, including the ability to import a set of qualifications and save them to the assigners' accounts, specify the type of link between a learning outcome and a skill from ESCO, search the ESCO database directly in the tool - especially useful when the machine learning model did not recommend anything adequate - and finally, export the results and determine the current status of the links (“in progress”, “complete” etc.).
The links between the IQR and ESCO that were developed in the second phase are intended to be used to retrain the machine learning model so that automatic recommendations will be more accurate in the future versions of the tool. The third phase of the pilots has recently been announced - its launch is planned for the first quarter of 2022 and the team from Poland will probably take part in it. During the next phase, we will likely learn more about the impact of our existing work on the Commission's new tools.
2. What data from the IQR databases did you use for testing?
For both pilots, we sought to select qualifications in such a way as to represent as broadly as possible the potential difficulties arising from the differences in qualification descriptions. In parallel to the pilots of the ESCO tool, our team was analysing the IQR data to assess the similarity and then cluster the qualifications using available artificial intelligence techniques.
The motivation behind analysing the similarity of the qualifications were two applications "Compass" and "Compass of Sectoral Education" we were developing, which were intended to use a graphical interface to show the IQR data based on grouping, which would allow browsing groups of qualifications that are related in some way - for example, coming from the same area of the economy. Thanks to these analyses, we were able to make some observations, e.g., that the way qualifications are described in the IQR varies significantly by category and author - both in terms of the style and language used, as well as the number of learning outcomes present in the description. As a result, the algorithms that did not consider the semantics of learning outcomes, but only the words and phrases used in the description, initially tended to create groups of qualifications belonging to the same category (e.g. sector education) or to create groups that were presumably developed by the same institutions. It wasn't quite the result we expected. Rather, we expected that the domain-specific vocabulary found in the qualification descriptions would be sufficient for artificial intelligence to create groups more reflective of industries or sectors of the economy, or, alternatively, that the qualification groups would vary according to the complexity of the knowledge, skills and social competences required.
For the purposes of the "Compasses" developed in the project, we also explored a new class of language models (e.g. BERT), which handle text semantics very well. In our case, while they enabled appropriate modelling of qualifications to determine their similarity to each other by industry, capturing the differences between qualifications according to their assigned PQF level, based on the language alone, continues to be extremely challenging.
In addition, in preparation for both pilots, we have been looking a bit at ESCO resources in terms of referencing them to the qualifications in the IQR. In particular, we noticed a number of skills in ESCO for which there are no equivalents in the IQR (at least for now), and that there are often differences in the level of detail of the descriptions in the two databases (e.g., "creates and restores backups'' from the IQR vs. "perform backups'' from ESCO)
While reflecting on the above work, we adopted several criteria, which were intended to help us select a small set of qualifications representing different aspects of the Integrated Qualifications System and allowing reliable testing of the Commission's IT tool in different situations. For the pilot we selected 26 qualifications from various categories (sectoral education, market, regulated, etc.), representing as many different branches of economy as possible (IT, medicine, automotive, etc.), assigned to different levels of the Polish Qualification Framework; we selected qualifications that require performing simple tasks such as "organizes the workplace", but also complex ones with specialized vocabulary, such as "recognizes the psychooncological situation of a patient and his/her reaction to the disease and the treatment process", as well as qualifications that differ in terms of the length of the descriptions of learning outcomes.
3. What difficulties/challenges have you encountered during the pilot and, in particular, while using the tool developed by the EC to link the learning outcomes to ESCO skills?
During the first stage, it was extremely important for us to establish when we can even say that two texts are about the same thing, that is, when they actually define the same skill. When thinking about matching, are we looking for literally the same skill descriptions, or, because similar things can be described in different ways, does semantics play a key role? If semantics, how do we define the boundary between an exact match and merely a very close match? Finally: how relevant is the context of a given phrase when literally matching, for example, when comparing "team collaboration" from an IQR qualification from the sport sector with "team collaboration" from an ESCO occupation from the IT sector, are we really talking about the same type of collaboration considering the different fields? The more we confronted the IQR and ESCO data, the more we noticed situations where a zero-sum approach is not sufficient to determine the relationships that occur. On the other hand, quite a few matches were obtained by determining the containment relationship (i.e., whether the meaning is broader or narrower; for example: the scope of "analyses customer requirements for the website and suggests solutions" from the IQR is contained within the scope of "identify customer requirements" from ESCO).
The second challenge was the trust in the machine learning model. The matches that the artificial intelligence within the tool recommended most were often not the best ones. It was relatively easy to be tempted by some pretty attractive looking model prompts, take one of the top ones, identify the relationship, and move on to matching the next learning effect. The challenge was that often these really best matches were either only further down the list of skills proposed by the model, or not on the list at all - as a result, without very good knowledge of the contents of both databases, i.e. the IQR and ESCO, it was relatively easy to miss the right match.
4. During the pilot work, you tested an interesting solution using the BERT model. You shared the results of this test with the EC as part of the pilot findings. Can you tell us more about this test? What did you test and what was the result?
As I mentioned, the use of machine learning in the tool prepared by the Commission did not produce results spectacular enough to significantly speed up the merging process, let alone to automate it completely. Nevertheless, the very idea of automating such a process and "confronting" the two databases with each other seemed to us to be an extremely attractive idea - such a mechanism could be a fantastic solution, for example, creating a skills ontology, examining the demand for skills, or comparing qualifications in the IQR.
During the period when the Commission was piloting the tool, new language models based on "transformer" architecture began to emerge in the world of natural language processing - the artificial intelligence branch of computational linguistics - that immediately trumped existing models in a variety of tasks, such as next-sentence prediction, text summarization, translation, and paraphrase detection. An example of a model built on the transformer architecture is exactely the BERT model that we used to create our own prototype of a mechanism for linking learning outcomes and ESCO skills.
To be more precise, we used a ready-made sentence-BERT (sBERT) model - a multilingual model tuned for the task of detecting synonymous sentences. This means that modeling learning outcomes and skills, which are almost always expressed as single sentences, is relatively "natural" for such a model, or, to put it more technically, it probably allows a more accurate vector representation of them than other models based on similarity of single words. The authors of the model indicate that the model can be used to determine specifically the semantic similarity between sentences and search for paraphrases.
As I mentioned, sBERT is a multilingual model: it works on more than 100 languages. This means that the texts that the model takes for comparison on input do not need to be in the same language at all to correctly determine their semantic similarity. In this way, we reduced the influence of one more factor that affected the quality of matches in the ESCO tool - the quality of the translations. Unfortunately, some of the ESCO translations into Polish contained errors, which made the experts' work difficult. Therefore, being able to use the original ESCO texts in English, potentially provided a chance to find matches that were difficult to catch if the expert used only the Polish wording from the IQR and ESCO.
For each learning outcome that we submitted for merging, we generated a list of candidate ESCO skills satisfying an arbitrary cosine similarity threshold. The results exceeded our wildest expectations. Our observations indicated that if there was a perfect match between the IQR and the ESCO, the right candidate almost always appeared in the first three positions. The model performed very well in translating and interpreting the semantics of sentences derived from the context. As an example, consider the learning outcome of "design a site mockup." In this case, the learning outcome comes from the qualification "Website Design", and the Polish word "witryna" can mean both a website and a store window. The prompts generated by the Commission tool interpreted the word "witryna" as a storefront every time, regardless of the context. In contrast, sBERT immediately suggested the skill "create website wireframe" in the first position, which proved to be the best possible match. Our appetites were thus stimulated.
While testing our mechanism, we also tried to select cases that we thought had already been studied and where experts felt that, for a given learning outcome, there was no equivalent in the ESCO; an example of such an outcome could be "Student respects professional confidentiality". The Commission's ML algorithm for this effect only suggested "perform green machining", while another mechanism in the search-based tool suggested skills such as: "work in a vocational school", "assess students", "manage sporting careers". None of the proposals were even close enough to be considered similar. Consequently, a person who is not familiar enough with the ESCO resources to remember all of the skills present in the skill base concluded that there was no appropriate match for the learning outcome under scrutiny. And here the model gave us a surprise and generated candidates that may seem fitting, ie : "observe confidentiality", "ensure information privacy", "act discreetly".
The prompts generated by sBERT, while not accurate enough, began to be extremely useful. They were not accurate, because while the model was able to generate a list of very reasonable prompts, it still could not fully automate the merging process by selecting only the best candidate or candidates. They were useful because the moment we trusted the generated prompts, it made our linking work much faster.
I believe these examples show how much magic can happen in today's neural networks, which are constantly evolving and companies are racing to create more powerful and intelligent models. In our case, the ESCO skills prompting mechanism built on sBERT became the primary tool used by our experts during the pilots, and it significantly facilitated and accelerated our work. It is important to remember, however, that the "power" of these models has another side and often involves the need for powerful computer resources to use them in a reasonable amount of time (processing our collections was a multi-hour process). Hence, employing them in a production environment, where the user expects almost immediate results, is still quite a challenge.
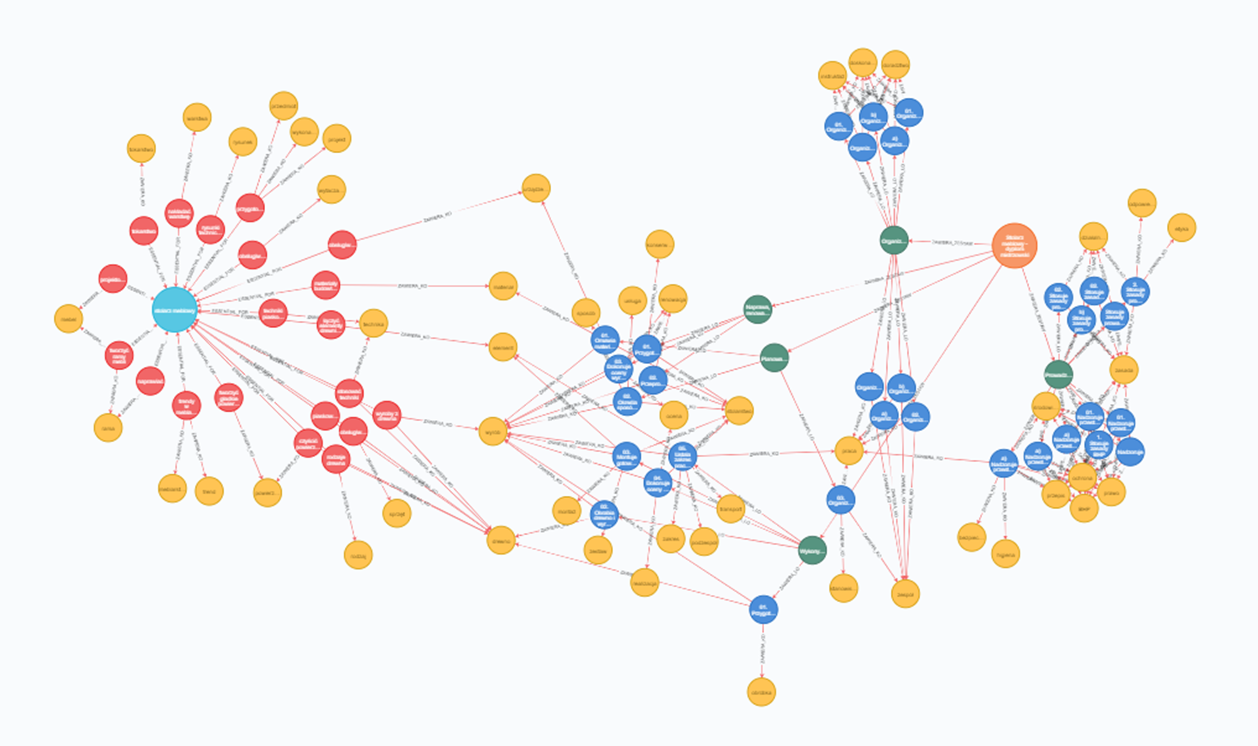
Graphical representation in the form of a diagram of relations between the skills of the occupation "cabinet maker" in the ESCO classification and the learning outcomes for the IQR qualification "carpenter - master craftsman diploma".
Orange dot - the IQR qualification
Green dots - sets of learning outcomes for the IQR qualification
Blue dots - learning outcomes of the IQR qualification
Yellow dots - knowledge objects; nouns in their base forms extracted from the learning outcomes of the IQR qualification
Light blue dot - the ESCO occupation
Red Dots - skills for the ESCO occupation
Yellow dots - knowledge objects; nouns in their base forms, extracted from the skills of the ESCO occupation